
データエンジニアの @reonah6 です。
2024/07の上〜中旬にかけて、AWS/Azureの東京リージョンで、Databricks のサーバレスコンピュート(for インタラクティブなNoteBook/Job)がロールアウトされたので、コストの確認方法をまとめてみました。
ぜひ、ご一読ください。
SalesNowという会社でプロダクトのPMをしている、石井(@yusuke_ishi_pdm)といいます!
私たちは「誰もが活躍できる仕組みをつくる。」というミッションを掲げ、アナログで非効率なセールスの働き方を変えるべく、日本国内全ての約540万社の情報を確認できる企業データベース『SalesNow(セールスナウ)』を運営しています。
今回は膨大な法人データベースを持つ当社で取り組んだLLMの失敗事例と活用事例、それによる成果について共有できたらと思います。
少しでもお役に立てたら幸いです!
(感想をXでポストしてくれると嬉しいです。メンションも嬉しいです)
---------------------------------------------------------------------------------------
こんな人に読んでほしい
・LLMをビジネス価値に繋げたい方
・企業データに興味がある方
・データエンジニア、データサイエンティストといったデータ領域に興味のある方
---------------------------------------------------------------------------------------
今回は大きくLLM活用においては3つの検証を行い、ビジネス価値に繋げる事ができました。詳細に関しては、以下のNoteに記載をしておりますのでぜひ読んでみてください!
またプロダクトの成長に伴い、データベースの中長期的な競争優位性の構築や、開発プロセスの継続的な改善、組織力の向上を目指して、ソフトウェアエンジニア、データエンジニア、データサイエンティストを積極的に採用しています!

Web バックエンドのテストコードを書く場合、その多くは DB に依存していることが多いです。 DB 関連のテストは、テストデータの準備やテストケース毎の DB 処理化を適切に行うことが重要ですが、手間がかかる場合あるため、Mock で擬似的にテストしてしまうことも多いかと思います。
ただ、Mock を使ったテストは本質的な問題を検知できない意味のないテストになってしまう可能性があり、可能な限り DB の Mock を行わずに、実際の DB を使用してテストすることが望ましいと考えています。
本記事では、pytest、sqlalchemy、PostgreSQL を使った場合に、テストケース毎に DB を簡単に初期化しつつ、テストケース毎の前提データ登録も簡単うことでテスト開発体験を向上させる方法を紹介します。
本記事では、以下の環境を前提として説明いたします。
pytest で効率的なテストを実装するためには、conftest.py や fixture の理解が重要です。
基本的な説明は以下に詳しく記述しているので参照いただければと思います。
conftest.py と fixture を使うことで、テスト用 DB のセットアップやテストデータ登録をシンプルに記述することが可能です。
https://zenn.dev/tk_resilie/articles/python_test_template
特段のセットアップをせずに DB 連携ありのテストケースを pytest を実行した場合、ローカル開発環境で使用している DB を使用することになります。ローカル開発環境の DB の状態はテスト実行によって都度変更されてしまう場合があり、毎回テスト結果が変わってしまう恐れがあります。 そのため、テスト実行毎に状態が初期化されるテスト用 DB をセットアップできることが望まく、これを簡単に行うことができる以下のライブラリが提供されています。
このライブラリを使うことで、テスト毎に毎回データがリセットされるテスト用の DB を扱う fixture を簡単に作ることができます。 テスト用 DB の fixture を使用するとローカルに docker 等で構築した postgresql サーバーに対して接続して、1つのテストケース毎にテスト用の databse を作成 → テスト実施 → database を削除という処理を行うことができます。
サンプルコードは以下の通りです。 ① の箇所で、pytest_postgresql の機能を使って、postgresql の fixture を作成しています。この fixture はテスト用 DB への接続情報を保持し、databse のセットアップやテスト後の database 削除処理を行います。 ② では ① で作成した postgresql_fixture を使って、各テストから直接呼び出す fixture を定義しています。 この db fixture では、テスト用のテーブルの作成を行い DB セッションを返しています。 今回は sqlalchemy を使用しているため、create_all 関数を使って、sqlalchemy の model で定義されたテーブルを全て作成するようにしています。
tests/conftest.py
from typing import Any, Generator import pytest from app.db import Base from pytest_postgresql import factories from sqlalchemy import create_engine from sqlalchemy.orm import Session, sessionmaker from sqlalchemy.pool import NullPool from app.models.models import Team # ①ライブラリを使ってテスト用のDBをセットアップするためのfixtureを作成 # 既定ではdbname=testでDBが作成されテストケースの実行毎にDBは削除され1から再作成される postgresql_noproc = factories.postgresql_noproc() postgresql_fixture = factories.postgresql( "postgresql_noproc", ) # ②pytest.fixtureのデコレーターを付与した関数はfixture関数になる @pytest.fixture def db( postgresql_fixture: Any, ) -> Generator[Session, None, None]: """テスト用DBセッションをSetupするFixture""" # 接続URIを作成 uri = ( f"postgresql://" f"{postgresql_fixture.info.user}:@{postgresql_fixture.info.host}:{postgresql_fixture.info.port}" f"/{postgresql_fixture.info.dbname}" ) # engineを作成 engine = create_engine(uri, echo=False, poolclass=NullPool) # SQLAlchemyで定義しているテーブルを全て作成する Base.metadata.create_all(engine) SessionFactory = sessionmaker(autocommit=False, autoflush=False, bind=engine) # Sessionを生成 db: Session = None try: db = SessionFactory() yield db db.commit() except Exception: db.rollback() finally: # teardown db.close()
テストに使用するサンプルのテーブル情報は以下の通りです。
app/models/models.py
from app.db import Base from sqlalchemy import Column, DateTime, Integer from sqlalchemy.dialects.postgresql import TEXT from sqlalchemy.sql.functions import current_timestamp class Feature1Sample(Base): """feature1用のサンプルテーブル""" __tablename__ = "feature1_sample" id = Column(Integer, primary_key=True) column1 = Column(TEXT) column2 = Column(TEXT) created_at = Column( DateTime(True), server_default=current_timestamp(), nullable=False ) updated_at = Column( DateTime(True), server_default=current_timestamp(), onupdate=current_timestamp(), nullable=False, )
テスト毎に固有のテストデータを登録する部分は、バックエンドのテストにおいて非常に重要な部分です。pytest では conftest.py にテストデータ登録処理を fixture として記述することで、わかりやすくデータを管理することができます。 下記ソースコードの ① では、テストケース毎のテストデータ登録用の fixture を定義しています。この fixture をテストケースから呼び出すことで、テストケース実行前に、任意のデータを登録(Insert)することができます。
全ての登録処理を ① にまとめて記述するることもできますが、複数のテーブルに対してデータを Insert する場合にわかりずらくなるため、② のように関数を分けて実装するとわかりやすいです。 この conftest.py は feature1 の配下に配置されているため、feature1 配下のテストケースからしか読み込まれない仕様になっています。これにより、テストデータのスコープを制限することができ、意図しない依存関係が生まれないようにしています。
tests/feature1/copnftest.py
import pytest from app.models.models import Feature1Sample from sqlalchemy.orm import Session # ①テストケース毎のテストデータInsert用のfixture @pytest.fixture def setup_db_for_test_feature1( # fixture: db(テスト用DBのセッション) db: Session ) -> None: _insert_feature1_sample(db) # ②各テーブル(Model)へのデータInsert処理 def _insert_feature1_sample(db: Session) -> None: data = [ Feature1Sample(column1=f"column1_{i}", column2=f"column2_{i}") for i in range(1, 4) ] db.add_all(data) db.commit()
テストケースの実装では、1つのテスト対象の関数に対して、複数のパラメータパターンでテストしたい場合が多いですが、普通に記述してしまうと、多くの冗長なテスト関数を記述することになり、保守性が悪化します。
そこで、同じテスト対象の関数に対する複数のパラメータのテストを1つのロジックで共通化するために parametrize を使用しています。 以下 ① のように@pytest.mark.parametrize のデコレータに対して、パラメーターの引数名、パラメータ配列の順で定義します。 配列で定義した引数名は、② のテストロジックの引数に同名で定義する必要があります。
pytest.param ではパラメータセットを定義します。引数の定義と同一順序で値を記述します。今回の例でいうと、"id", "expected_hit", "expected_column1", "expected_column2"の順でパラメータを記述します。 末尾の id はテストケース毎の任意の識別 id を定義できます。
id 定義は必須でありませんが、定義することで以下のようにテスト関数内の任意のパラメータのテストのみを選択的に実行することもできます。
pytest tests/feature1/test_feature1.py::test_get_feature1_by_id[success]
macOS の場合は以下のように[]にエスケープが必要です。
pytest tests/feature1/test_feature1.py::test_get_feature1_by_id\[success\]
以下の例では、② 以降で定義したテストロジックを2つのパラメータパターンで実行することができます。
parametrize によるテスト関数の共通化は、コードの冗長性を排除して保守性を向上させる効果がありますが、過度な共通化は、逆に保守性および可読性の悪化を招く可能性があるため、共通化が難しい場合はテスト関数を分ける判断も重要です。
import pytest from app.crud.feature1 import get_feature1_by_id from fastapi import status from fastapi.testclient import TestClient from sqlalchemy.orm import Session # ①parametrizeを使用することで、1つのロジックで複数のパラメータをテストできる @pytest.mark.parametrize( # テストケースで使用する引数名を配列で指定する ["id", "expected_hit", "expected_column1", "expected_column2"], # パラメータを指定する(引数名と同じ順番で指定する。idはテストケースのID) [ pytest.param(1, True, "column1_1", "column2_1", id="success"), pytest.param(99, False, None, None, id="not_found"), ], ) # ②テストロジックはparametrizeに指定したパラメータの配列分だけ実行される def test_get_feature1_by_id( # fixture: db(テスト用DBのセッション) db: Session, # fixture: setup_db_for_test_feature1(テストデータInsert) setup_db_for_test_feature1: None, # parametrizeで指定した引数名を指定する(順番が一致している必要はないが指定した引数は全て記述する必要がある) id: int, expected_hit: bool, expected_column1: str | None, expected_column2: str | None, ) -> None: feature1_obj = get_feature1_by_id(db, id=id) if expected_hit: assert feature1_obj is not None assert feature1_obj.column1 == expected_column1 assert feature1_obj.column2 == expected_column2 else: assert feature1_obj is None
DB を docker で構築する場合の docker compose のサンプルです。
テスト実行前にdocker compose up -d で起動しておきます。
compose.yml
services:
db:
image: postgres
volumes:
- postgres-volume:/data/postgres
environment:
POSTGRES_DB: app
POSTGRES_USER: postgres
POSTGRES_PASSWORD: pass
PGDATA: /data/postgres
POSTGRES_HOST_AUTH_METHOD: "trust"
ports:
- "5432:5432"
networks:
- api-network
networks:
api-network:
driver: bridge
volumes:
postgres-volume:
テストを実行するためのコマンド例は以下の通りです。
# 必要なライブラリのインストール $ python -m venv venv $ . venv/bin/activate $ pip install pytest pytest-postgresql sqlalchemy # テスト実行(全テストケース) $ pytest tests # テスト実行(特定のテスト関数の指定したパラメータIDのみ実行) $ pytest tests/feature1/test_feature1.py::test_get_feature1_by_id[success]
pytest、sqlalchemy、PostgreSQL を使った場合の効率的な実装方法について説明しました。 Web バックエンドのテスト実装は、DB 部分を適切に対応できると、一気にテスト体験が向上するため、ぜひお試しください。 また今回は PostgreSQL を使用しましたが、MySQL 向けの同等のライブラリが提供されているため、同じように実装が可能です。 テスト体験の向上は、テストカバー率の向上につながりアプリケーションの品質向上につながると考えております。
SalesNowのプロダクトや文化についてもっと知りたいと思われた方は、カジュアル面談でお話しましょう。 https://open.talentio.com/r/1/c/quickwork/homes/4033

株式会社SalesNowでデータ部門の技術顧問をしている島田(@smdmts)です。
担当領域はデータ処理基盤、Webサービス開発、データ組織作りなどで、SalesNowでは1年半にわたり、データ処理基盤の構築/運用、データを活かした新機能の提案/実装、開発メンバーの採用/教育/チーム運営まで、幅広く業務サポートを行っています。
SalesNowでは、BtoBセールスの負の体験を解消し、社会の生産性を劇的に向上させるべく、「SaaS + Database」を軸とした企業データベース『SalesNow(セールスナウ)』を展開しています。
昨年(2023年)12月14日に、Databricks様、Forkwell様、Timee様のご厚意で、「データ基盤 x LLM」勉強会の場で弊社のLLM活用事例をLTさせていただきました。
この記事では、当日の登壇資料をもとに、SalesNowのデータ基盤とLLM活用について簡単にご紹介いたします。
SalesNowのデータ基盤は、クローラにScrapy、処理基盤にDatabricksを利用しています。 法的・技術的に認められる範囲で、公開情報となるWebページをクローリングし、乱雑な文字列データを構造化してデータベースに格納しています。
次の図に示すとおり、クローリングしたデータをAWSのAuroraに一次領域として格納し、Delta Lakeに変換して、アプリケーション側のAuroraやElasticsearchに転送する構成になっています。
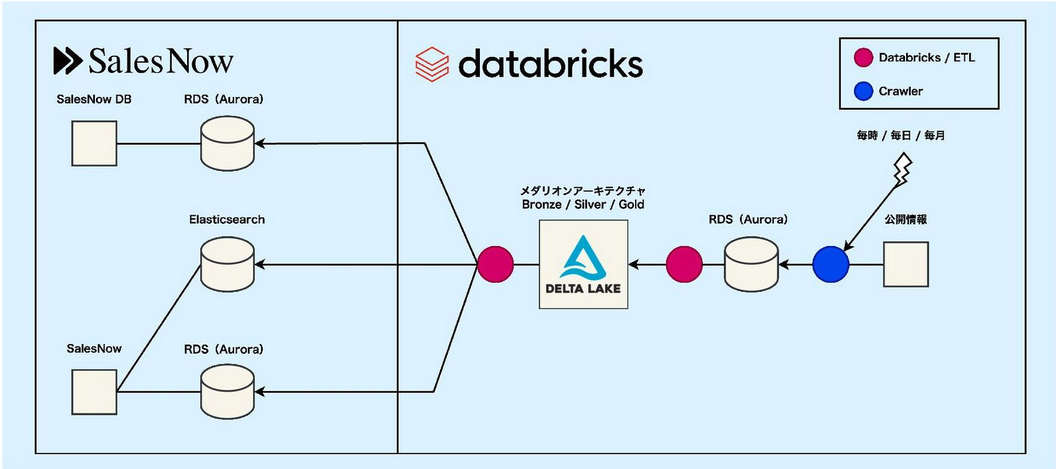
Auroraは、データ量が増えても128TiBまで自動拡張されるスケーラブルなSQLエンジンで、トランザクション処理も可能なため、取得量が変動するデータの一次保管領域に適しています。 この構成はクローラとデータ処理を疎結合とし、AuroraからDelta Lakeに変換することで、分散計算機による大量データ処理を可能にする設計です。
クローラには、HTMLを構造解析し、表形式の構造化データに変換する処理を施しています。 クローリングしたデータは必ずしも構造化されていないため、システムから利用しやすい形式に変換する必要があります。 たとえば年収の表記には、「n万円」、「nnn,nnn円」、「n万円〜」「n万円以上」などの表記の揺れがあり、これらを標準化(ノーマライズ)する必要があります。
データの標準化には、メダリオンアーキテクチャの利用が有効であると考え、データ基盤を構築しました。 メダリオンアーキテクチャは、Bronze(生ログ)、Silver(クレンジングした中間テーブル)、Gold(目的別に特化したテーブル)の3層構造で、データを抽象度毎に管理するアーキテクチャです。 本来メダリオンアーキテクチャは、ログの解析処理に用いられますが、乱雑なデータをシステムで利用可能な形に加工する場合にも有効です。 年収データをシステムで利用するためには、数値型でデータベースに格納する必要がありますが、その加工処理はBronzeからSilverへのデータ移行時に行われます。
しかし、日本語には同意語・類語が無数にあり、事前に全ての表記法が分かっている訳ではないため、変換パターンを完全に網羅はできません。 そこでDatabricksが提供する機能を用いて、Silverステージにあるデータの何パーセントが適正値であるかを分析・可視化して、その数値改善によるデータ品質の向上を行っています。 年収データの場合、数値型への変換に失敗したデータや、相場から大幅に乖離した(入力ミスと思われる)データなどが非適正値と判断されます。
データに特化したプロダクト開発では、データ品質の数値化は重要であり、可視化された数値をもとに改善状況の進捗確認をしています。
SalesNowでは、自動化されたクローリングシステムと人の手による入力という2つの方法でデータを収集し、データ処理基盤を通して利用者にとって価値の高い形に加工することで、即時性が高く正確な情報提供を実現しています。 このデータ蓄積作業は非常にコストが掛かるため、LLMを活用した代替機能の検討を行いました。
一般的に、データプロダクトの開発には、ふるまい要件(アプリケーションで達成したいふるまい)とデータ要件(ふるまい要件で必要となるデータ)の2つの要件があります。

今回のLLM活用でのふるまい要件は、「日本の全企業の会社概要をSalesNow上に表示したい」ことです。 日本全国には約550万社の企業があり、これらの会社概要文を人の手で作成するのはコスト的に現実的ではありません。 企業情報を見ながら概要文を作成し、正しいかを別人がダブルチェックするオペレーションをLLMで代替えできれば、データ作成を自動化できます。
SalesNowのデータ要件では、「高品質であること」が絶対的に求められます。高品質データとは次のようなものです。
以上をふまえ、「データ品質の担保」と「コスト抑制」 の観点から、LLMで代替可能な作業範囲を検証します。
今回の検証では、文書生成をChatGPT、品質評価をGoogle PaLM2に置き換えました。
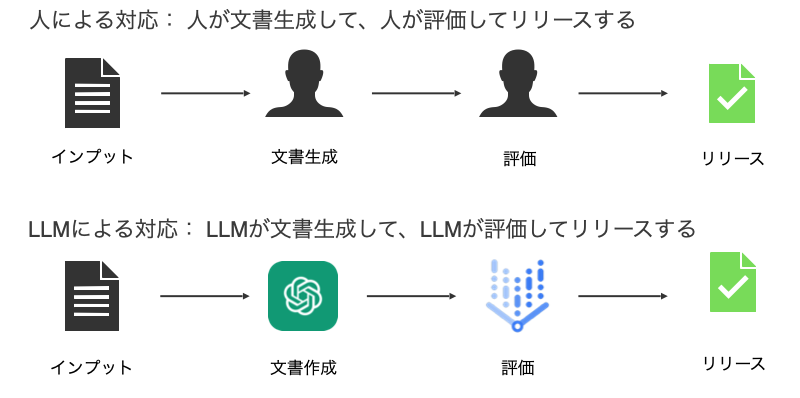
この手法は、LLM-as-a-Judgeと呼ばれており、LLMが出力した結果をLLMに評価させるアプローチです。 データベースに格納済みの企業データからLLMを用いて会社概要文を生成し、その品質をLLMに自動評価させます。
LLMは原理上、ハルシネーションが発生することが知られており、生成時のみならず評価時でも誤った情報が出力されることを前提としたシステム構築が必要です。 LLMによる成果物が本当に利用者にとって高品質であるかを判断するためには、最終的には人による確認が必要です。 SalesNowではデータリサーチャと呼ばれるデータの調査を担当する専門職種が設置されており、本当に高品質であるかを人力評価していただきました。 (以下のプロンプト例は、実際に使用したものではなく概略です。)
このような指示で会社概要文の生成、評価、人による判断を行った結果、次のような結果になりました。
ここから生成プロンプトや評価プロンプトをチューニングすることにより、文書生成や評価の精度向上が期待できるため、今後への課題として絶賛検証中です。
SalesNowのデータ基盤とLLM活用について簡単に紹介させていただきました。 検証結果の続きを知りたい方は、こちらのスライドをご覧ください。
データ基盤の構築や、データを軸としたプロダクトづくりに興味がある方は、ご意見、ご感想等、コメントにて頂けると嬉しいです。
SalesNowの開発組織は、最新のデータベース技術を積極的に取り入れ、技術を通じてBtoBセールスの負の体験を解消し、社会の生産性を劇的に向上させることに取り組んでいます。
プロダクトの成長に伴い、データベースの中長期的な競合優位性構築や、開発プロセスの持続的な改善や組織力の向上を目指し、ソフトウェアエンジニア・データエンジニア・データサイエンティストなどを積極採用しています。
技術選定、アーキテクチャ設計、開発プロセスの改善、開発組織の強化などを担当していただき、CTO/VPoE/テックリードなどの上位ポジションに挑戦することも歓迎しています。
カジュアルにまずはお話しましょう!

株式会社SalesNowではFastAPIを使ってバックエンドを構築しています。
FastAPIを使うことでSwagger UIを自動的に生成することができ、APIのドキュメント化や検証に非常に有用ですが、既定では1つのSwagger UIに全てのWebAPIが羅列されるため、規模が大きくなるにつれて、管理が辛くなることが想定されます。
SalesNowの提供するWebシステムでは100以上のDBテーブル、300以上のWebAPIがあるため、機能ドメイン毎にSwaggerUIを分割して管理しています。
本記事では、この機能ドメイン等の単位でSwagger UIを分割して管理する方法を紹介します。
FastAPIはFastAPIクラスを使いappを作成し、このappに任意のPath関数を紐付けていくことでバックエンドを構築することができます。このapp毎にSwagger UIが作成されるため、機能ドメイン等の任意の単位で複数のFastAPIのappを作成し、ベースとなるapp(uvicornで起動するapp)に対して他のappをmountすることで、複数のSwagger UIを作成することができます。
ただし、この状態では、Swagger UI間のリンクが無く不便であるため、以下のコード例ではFastAPIのappのdescriptionに対して、Swagger UIへのリンクを生成するためのHTMLをセットして、Swagger UI上部に他のSwagger UIへのリンクを生成するようにしています。
コード例
# main.py from fastapi import FastAPI # appを定義 app = FastAPI(title="App") feature_app = FastAPI(title="App(/feature)") admin_app = FastAPI(title="App(/admin)") # Path関数を定義 @app.get("/") def base_app_root(): return {"message": "Hello World"} @feature_app.get("/") def feature_app_root(): return {"message": "Hello World"} @admin_app.get("/") def admin_app_root(): return {"message": "Hello World"} # BaseとなるAppに他のappをmountする app.mount("/feature", feature_app) app.mount("/admin", admin_app) APP_PATH_LIST = ["", "/feature", "/admin"] # Swagger間のリンクを作成 def _make_app_docs_link_html(app_path: str, app_path_list: list[str]) -> str: """swaggerの上部に表示する各Appへのリンクを生成する""" descriptions = [ f"<a href='{path}/docs'>{path}/docs</a>" if path != app_path else f"{path}/docs" for path in app_path_list ] descriptions.insert(0, "Apps link") return "<br>".join(descriptions) app.description = _make_app_docs_link_html("", APP_PATH_LIST) feature_app.description = _make_app_docs_link_html("/feature", APP_PATH_LIST) admin_app.description = _make_app_docs_link_html("/admin", APP_PATH_LIST)
コマンド実行例
# venv作成 $ python -m venv .venv # venv有効化 $ . .venv/bin/activate # packageインストール $ pip install fastapi uvicorn # uvicornでfastapiを実行 $ python -m uvicorn main:app --port 8080 --reload
http://localhost:8080/docsにアクセスすると、以下のような画面が表示されます。
App毎に別のSwagger UIが作成され、その間の相互リンクが画面上部に生成して、ページ間の移動を容易にしています。
baseのAppのSwagger UIです。画面上部にURLリンクが表示されており、これをクリックすることで複数のSwagger UI間を相互に移動することができます。

featureのAppのSwaggerUIです。

先程の実装でも動作はしますが、Appが多くなった場合に管理が煩雑になる恐れがあるため、FastAPIAppManagerクラスを作成して、管理を容易にしたものは以下の通りです。
複数のappを管理するためのFastAPIAppManagerクラスを作成して、app設定のコピーやSwagger UI間リンクの生成を行っています。
# main2.py (main.pyの改良版) from fastapi import FastAPI from app_manager import FastAPIAppManager # appを定義 app = FastAPI(title="App") feature_app = FastAPI() admin_app = FastAPI() app_manager = FastAPIAppManager(root_app=app) # Path関数を定義 @app.get("/") def base_app_root(): return {"message": "Hello World"} @feature_app.get("/") def feature_app_root(): return {"message": "Hello World"} @admin_app.get("/") def admin_app_root(): return {"message": "Hello World"} # FastAPIAppManagerにappを追加することで、Linkの自動生成を行う app_manager.add_app(path="/feature", app=feature_app) app_manager.add_app(path="/admin", app=admin_app) app_manager.setup_apps_docs_link()
# app_manager.py from fastapi import FastAPI class FastAPIAppManager: """複数のFastAPI appを管理するためのManagerクラス""" def __init__(self, root_app: FastAPI) -> None: self.app_path_list: list[str] = [""] self.root_app: FastAPI = root_app self.apps: list[FastAPI] = [root_app] def add_app(self, app: FastAPI, path: str) -> None: self.apps.append(app) if not path.startswith("/"): path = f"/{path}" else: path = path self.app_path_list.append(path) # ベースとなるappのTitle等を引き継ぐ app.title = f"{self.root_app.title}({path})" app.version = self.root_app.version app.debug = self.root_app.debug self.root_app.mount(path=path, app=app) def setup_apps_docs_link(self) -> None: """他のAppへのリンクがopenapiに表示されるようにセットする""" for app, path in zip(self.apps, self.app_path_list, strict=True): app.description = self._make_app_docs_link_html(path) def _make_app_docs_link_html(self, current_path: str) -> str: """openapiの上部に表示する各Appへのリンクを生成する""" descriptions = [ f"<a href='{path}/docs'>{path}/docs</a>" if path != current_path else f"{path}/docs" for path in self.app_path_list ] descriptions.insert(0, "Apps link") return "<br>".join(descriptions)
上記のソースコードは以下で公開しております。
https://github.com/QuickWorkInc/tech-blog-sample-code/tree/master/sample_codes/fastapi_multi_appsgithub.com
FastAPIでWebAPIを複数のSwagger UIに分割して管理する方法を紹介しました。
ご意見、ご感想等、コメントにて頂けると嬉しいです。
SalesNowの開発組織は、最新のデータベース技術を積極的に取り入れ、技術を通じてBtoBセールスの負の体験を解消し、社会の生産性を劇的に向上させることに取り組んでいます。
プロダクトの成長に伴い、データベースの中長期的な競合優位性構築や、開発プロセスの持続的な改善や組織力の向上を目指し、ソフトウェアエンジニア・データエンジニア・データサイエンティストなどを積極採用しています。
技術選定、アーキテクチャ設計、開発プロセスの改善、開発組織の強化などを担当していただき、CTO/VPoE/テックリードなどの上位ポジションに挑戦することも歓迎しています。
カジュアルにまずはお話しましょう!
こんにちは。SalesNowの代表の(@Ats_mrk)です。
僕たちは、B2Bセールスの働き方を変える企業データベース『SalesNow(セールスナウ)』を展開しています。
本日よりこのSalesNow Tech Blogで、社内で取り組んでいる開発業務やUI/UXデザイン、PM(プロジェクトマネジメント)/PdM(プロダクトマネジメント)など、プロダクト開発に関連することを中心に発信していきます。
最初の記事ということで、今回はTech Blogを開始した背景を書いていきます。
SalesNowでは、これまでにも弊社のサービスや企業文化に関する情報を、コーポレートサイトや各自のX(旧Twitter)アカウント、事業・組織に関する情報をまとめたCampany Deck、会社の雰囲気やカルチャーを伝えるnote、大事にしている価値観をまとめたCulture Deckなどを通じてお伝えしてきました。こちらに加え、Tech Blogを通して「プロダクトチームが取り組んでいる課題や、課題解決に向けてどのようなアプローチをしているのか」をより細かく伝えていきたいと思います。
SalesNowでは「言語化とナレッジシェア」を大事にしています。社内外問わず、情報をオープンにすることでSalesNowに関心を持ってくれた人が、SalesNowがどのようなプロダクト開発をしてくれたか簡単にキャッチアップできるようにしたいと考えています。
SalesNowの開発チームが率先して言語化したナレッジをオープンに発信していくことにより、より多くの人がスタートアップ/セールス業界全体を良くしていける雰囲気作りをしていきたいと考えています。
各メンバーの情報発信によって自身が取り組んできた業務へのFB(フィードバック)が社外から得られ、それらがメンバー個人やチームに新たな気づきを促し、より良い開発組織へと成長していけると考えています。
また、社内向けの発信としてもメンバー一人ひとりが日々の仕事やプロジェクトで学んだこと、直面した課題、そしてそれをどのように解決しているかを共有する場としても、このTech Blogを活用していきます。
本日はSalesNow Tech Blogの開始のご挨拶をさせていただきました。今後は社内の様々な声や、SalesNowプロダクトに関する情報を共有していく予定です。
どうぞご期待ください!
SalesNowのプロダクトや文化についてもっと知りたいと思われた方は、カジュアル面談でお話しましょう。
