
はじめに
株式会社SalesNowでデータ部門の技術顧問をしている島田(@smdmts)です。
担当領域はデータ処理基盤、Webサービス開発、データ組織作りなどで、SalesNowでは1年半にわたり、データ処理基盤の構築/運用、データを活かした新機能の提案/実装、開発メンバーの採用/教育/チーム運営まで、幅広く業務サポートを行っています。
SalesNowでは、BtoBセールスの負の体験を解消し、社会の生産性を劇的に向上させるべく、「SaaS + Database」を軸とした企業データベース『SalesNow(セールスナウ)』を展開しています。
昨年(2023年)12月14日に、Databricks様、Forkwell様、Timee様のご厚意で、「データ基盤 x LLM」勉強会の場で弊社のLLM活用事例をLTさせていただきました。
この記事では、当日の登壇資料をもとに、SalesNowのデータ基盤とLLM活用について簡単にご紹介いたします。
SalesNowのデータ基盤
SalesNowのデータ基盤は、クローラにScrapy、処理基盤にDatabricksを利用しています。 法的・技術的に認められる範囲で、公開情報となるWebページをクローリングし、乱雑な文字列データを構造化してデータベースに格納しています。
次の図に示すとおり、クローリングしたデータをAWSのAuroraに一次領域として格納し、Delta Lakeに変換して、アプリケーション側のAuroraやElasticsearchに転送する構成になっています。
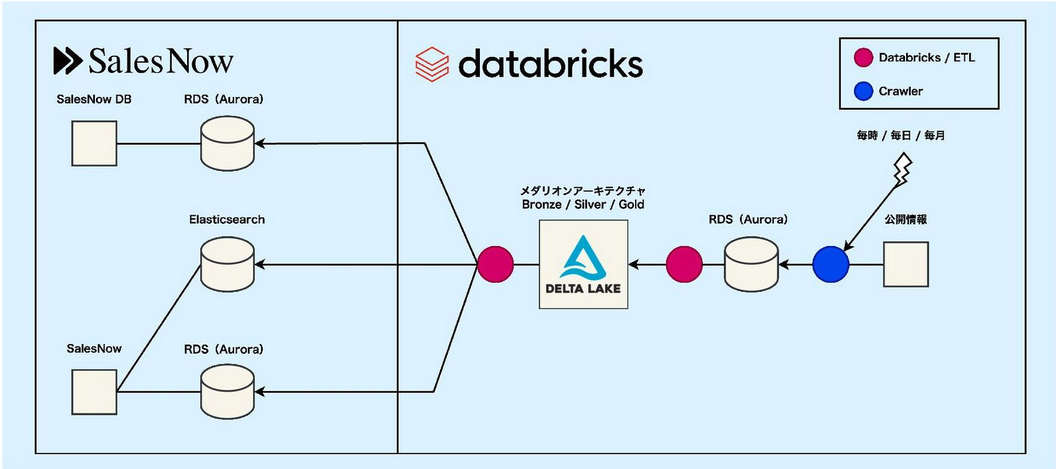
Auroraは、データ量が増えても128TiBまで自動拡張されるスケーラブルなSQLエンジンで、トランザクション処理も可能なため、取得量が変動するデータの一次保管領域に適しています。 この構成はクローラとデータ処理を疎結合とし、AuroraからDelta Lakeに変換することで、分散計算機による大量データ処理を可能にする設計です。
データ品質とメダリオンアーキテクチャ
クローラには、HTMLを構造解析し、表形式の構造化データに変換する処理を施しています。 クローリングしたデータは必ずしも構造化されていないため、システムから利用しやすい形式に変換する必要があります。 たとえば年収の表記には、「n万円」、「nnn,nnn円」、「n万円〜」「n万円以上」などの表記の揺れがあり、これらを標準化(ノーマライズ)する必要があります。
データの標準化には、メダリオンアーキテクチャの利用が有効であると考え、データ基盤を構築しました。 メダリオンアーキテクチャは、Bronze(生ログ)、Silver(クレンジングした中間テーブル)、Gold(目的別に特化したテーブル)の3層構造で、データを抽象度毎に管理するアーキテクチャです。 本来メダリオンアーキテクチャは、ログの解析処理に用いられますが、乱雑なデータをシステムで利用可能な形に加工する場合にも有効です。 年収データをシステムで利用するためには、数値型でデータベースに格納する必要がありますが、その加工処理はBronzeからSilverへのデータ移行時に行われます。
しかし、日本語には同意語・類語が無数にあり、事前に全ての表記法が分かっている訳ではないため、変換パターンを完全に網羅はできません。 そこでDatabricksが提供する機能を用いて、Silverステージにあるデータの何パーセントが適正値であるかを分析・可視化して、その数値改善によるデータ品質の向上を行っています。 年収データの場合、数値型への変換に失敗したデータや、相場から大幅に乖離した(入力ミスと思われる)データなどが非適正値と判断されます。
データに特化したプロダクト開発では、データ品質の数値化は重要であり、可視化された数値をもとに改善状況の進捗確認をしています。
データ基盤とLLM活用
SalesNowでは、自動化されたクローリングシステムと人の手による入力という2つの方法でデータを収集し、データ処理基盤を通して利用者にとって価値の高い形に加工することで、即時性が高く正確な情報提供を実現しています。 このデータ蓄積作業は非常にコストが掛かるため、LLMを活用した代替機能の検討を行いました。
一般的に、データプロダクトの開発には、ふるまい要件(アプリケーションで達成したいふるまい)とデータ要件(ふるまい要件で必要となるデータ)の2つの要件があります。

今回のLLM活用でのふるまい要件は、「日本の全企業の会社概要をSalesNow上に表示したい」ことです。 日本全国には約550万社の企業があり、これらの会社概要文を人の手で作成するのはコスト的に現実的ではありません。 企業情報を見ながら概要文を作成し、正しいかを別人がダブルチェックするオペレーションをLLMで代替えできれば、データ作成を自動化できます。
SalesNowのデータ要件では、「高品質であること」が絶対的に求められます。高品質データとは次のようなものです。
- 最新のデータ、かつ、誤りが無い
- 完全性(インテグラリティ)がある(重複や欠損が無い)
- 文章においては、主語や目的語の欠損が無い、意味が明瞭、誤字の少なさなど
以上をふまえ、「データ品質の担保」と「コスト抑制」 の観点から、LLMで代替可能な作業範囲を検証します。
- データ品質の担保:LLMの成果物が正しいかを確認し歩留まり率を算出する → 品質の数値化
- コスト抑制:人件費とAPI利用費用を比較する
今回の検証では、文書生成をChatGPT、品質評価をGoogle PaLM2に置き換えました。
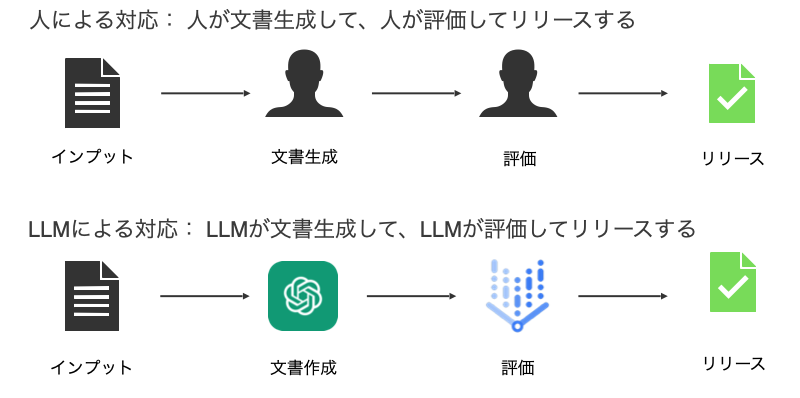
この手法は、LLM-as-a-Judgeと呼ばれており、LLMが出力した結果をLLMに評価させるアプローチです。 データベースに格納済みの企業データからLLMを用いて会社概要文を生成し、その品質をLLMに自動評価させます。
LLMによる文書生成と評価
LLMは原理上、ハルシネーションが発生することが知られており、生成時のみならず評価時でも誤った情報が出力されることを前提としたシステム構築が必要です。 LLMによる成果物が本当に利用者にとって高品質であるかを判断するためには、最終的には人による確認が必要です。 SalesNowではデータリサーチャと呼ばれるデータの調査を担当する専門職種が設置されており、本当に高品質であるかを人力評価していただきました。 (以下のプロンプト例は、実際に使用したものではなく概略です。)
- 生成プロンプト:以下の文章から第三者視点で会社概要文を生成してください。提供サービスや企業説明に重点を置き、本文中に無いものは一切使用しないでください。
- 評価プロンプト:企業の事業・商品・サービスが明確な場合に1点、企業情報が第三者視点で書かれている場合に1点、入力文書に会社概要と無関係な物が含まれていない場合に1点、合計3点で採点してください。また、日本語として適切ではない場合は0点としてください。
- リサーチャへの依頼:出力された文章と採点を鑑みて、顧客に提示可能な情報であるか判断してください。
このような指示で会社概要文の生成、評価、人による判断を行った結果、次のような結果になりました。
- 2点:「xx社は、プレスリリースや求人情報も掲載しています。」
- どの企業でも行っている一般的内容のため、会社概要としては不適切
- 2点:「xx社は、札幌で老人ホームと介護サービスを展開している会社です。」
- 調査の結果、札幌以外にも事業所があるため、説明不足
- 0点:「xx社は、金融機関として行動力みなぎるコミュニティバンクを実現します!」
- 企業理念としては適切だが、会社概要としては説明不足
- 3点:「愛知県に本社を置くxxxのトップシェア企業です。」
- 調査の結果、トップシェア企業では無かった
ここから生成プロンプトや評価プロンプトをチューニングすることにより、文書生成や評価の精度向上が期待できるため、今後への課題として絶賛検証中です。
まとめ
SalesNowのデータ基盤とLLM活用について簡単に紹介させていただきました。 検証結果の続きを知りたい方は、こちらのスライドをご覧ください。
データ基盤の構築や、データを軸としたプロダクトづくりに興味がある方は、ご意見、ご感想等、コメントにて頂けると嬉しいです。
SalesNowの開発組織は、最新のデータベース技術を積極的に取り入れ、技術を通じてBtoBセールスの負の体験を解消し、社会の生産性を劇的に向上させることに取り組んでいます。
プロダクトの成長に伴い、データベースの中長期的な競合優位性構築や、開発プロセスの持続的な改善や組織力の向上を目指し、ソフトウェアエンジニア・データエンジニア・データサイエンティストなどを積極採用しています。
技術選定、アーキテクチャ設計、開発プロセスの改善、開発組織の強化などを担当していただき、CTO/VPoE/テックリードなどの上位ポジションに挑戦することも歓迎しています。
カジュアルにまずはお話しましょう!